
Science is facing a crisis that costs an estimated $20 billion annually. A significant portion of published studies cannot be reproduced or replicated, undermining the research that drives innovation in medicine, policy, and business. To address this, Paul Litvak, PhD, and the Robyn Dawes Institute are building evidence.guide: an AI-powered tool that analyzes scientific papers, and predicts whether their findings will be replicable. Evaluating research at the scale the crisis demands—tens of thousands of papers, eventually millions—requires serious compute to match. Dispersed's distributed GPU network makes this pipeline economically viable, enabling evidence.guide to process research at a scale and cost that would otherwise be impossible.
Paul knows firsthand what happens when a business is built on research that doesn't hold up. As a co-founder of Rhythmic Health, he built a saliva-based health sensor using a promising technology called molecularly imprinted polymers, which are synthetic materials engineered to detect specific biological markers. The scientific literature suggested the technology was viable. Years of development and millions of dollars later, Litvak's team couldn't make it work, and neither could the researchers who had published the original claims.
That experience led Paul to an important question: if scientific research is the raw material that products, policies, and medical decisions are built from, how do we know when it is reliable? At the Robyn Dawes Institute—named for the psychologist who spent his career exposing the limits of human judgment—Paul now works on the solution.
Evidence.guide is the answer Paul is building. It pulls structured data from PDFs, runs quality checks on each paper, and uses machine learning to predict the likelihood of replicability. The goal is ambitious: to eventually create a “comprehensive, quality-weighted evidence base for science” by processing and evaluating every randomized controlled trial (RCT) ever published.
The problem evidence.guide is solving has two distinct layers: the scientific challenge of evaluating which research can be trusted, and the computational challenge of doing it at a scale that actually matters.
Science relies on replication, that is, the ability to repeat an experiment and get the same results. This is what separates science and guesswork; If an experiment can’t be repeated, its findings can’t be trusted. However, a 2016 poll of 1,500 scientists found the majority believe published results can't be consistently reproduced. The data backs this up: When researchers tried to replicate 100 psychology studies in the landmark Reproducibility Project, only about 40% of the attempts were successful. But what about the 60% that fail? The consequences of this are not abstract: replication failure costs an estimated $28 billion annually in the US alone in preclinical research. Moreover, the damage compounds when flawed findings make their way into clinical practice, policy decisions, or product development. For example, a clinician evaluating treatments for a patient relies on published evidence to make decisions. If that evidence doesn't hold up, the decision built on it doesn't either.
It’s worth mentioning that not all replication failures represent bad science. Sometimes, findings don't generalize across populations or contexts, and that's a meaningful result in itself. The problem is that we currently have no reliable way to distinguish between studies that failed to replicate for legitimate reasons and those built on shaky methods, statistical manipulation, or selective reporting.
In scientific literature, positive, surprising results are generally the ones that get published, cited, and covered. This can shape how data is analyzed as scientists search for something publishable within their research. They may test multiple hypotheses, run multiple analyses, and report only what worked. This is not done out of malice, but because the system rewards findings over rigorous scientific process. The cumulative effect is a literature that overstates certainty and understates doubt.

The warning signs of a flawed study fall into a few categories: statistical errors, methodological weaknesses, and transparency failures. Any one of these can undermine a finding. In practice, they often occur together.
Several approaches exist to address this problem. Open Science practices such as preregistration, data sharing, and registered reports have had a meaningful positive impact on study quality. However, enforcement of these practices is almost non-existent, and the underlying pressure to produce positive results remains intact. Meta-analysis, manual replication, and prediction markets are useful for evaluating existing research, but lack the ability to scale meaningfully. They are slow, expensive, labor-intensive, and dependent on human expertise.
Prediction markets, where people bet on the replicability of studies, achieve roughly 73% accuracy, but they depend on the knowledge of a small group of domain experts who can actually evaluate the science. This solution cannot scale significantly the way you could with a more general prediction market, as the participants need to have specialized knowledge; a layman predicting the replicability of a study is just noise. Evidence.guide seeks to match and eventually surpass this baseline at a fraction of the cost and a scale that human experts simply can't cover.
The scale of the challenge is almost impossible to overstate. Every year, hundreds of thousands of papers are published across dozens of fields. Evaluating current studies, nevermind the decades of accumulated literature already in existence, is a massive proposition. There are not enough people, money, or time in science to do this manually. No existing approach scales to this size, so Paul went looking for one.
Solving the scientific problem at scale creates a second layer of obstacles. Before you even begin to think about predicting replicability, you need to get the right data out of the study. To do this, you must contend with the often inscrutable PDF. Identifying statistical errors, methodological weaknesses, and replicability signals across tens of thousands of papers requires automated extraction of structured data from scientific PDFs. This is harder than it sounds.
Scientific papers are not standardized or presented in a structured format that is easily read programmatically. Tables vary wildly in format. Statistical reporting conventions differ across journals, subfields, and decades. Figures embed data that isn't captured in text. GROBID, the industry-standard open source tool for parsing scientific PDFs, fails to correctly extract data from studies about 20% of the time, and struggles particularly with tables, where much of the critical statistical data lives.
To address this need for more precise data extraction, evidence.guide adds a multi-model refinement layer, feeding extracted tables into large language models, including Gemini and Mistral, to improve accuracy. The goal is to extract accurate numbers and then be able to correctly interpret what those numbers mean.
Even with improved extraction, running multiple AI analysis layers across tens of thousands of papers simultaneously is computationally intensive. And at the scale evidence.guide is targeting (eventually millions of papers) traditional cloud infrastructure like AWS or Google Cloud could be prohibitively expensive for a small nonprofit operating with one full-time staff member and a handful of contractors.
Dispersed's distributed GPU network addresses both the cost and scale constraints that make traditional cloud infrastructure impractical for evidence.guide's workload. Unlike traditional cloud providers that operate their own expensive data centers, Dispersed acts as a marketplace by connecting users who need compute power with GPU owners with unused capacity to offer. For GPU-intensive processing at this scale, distributed compute networks like Dispersed offer significantly lower costs than hyperscalers.
Cost is only part of the equation. Dispersed offers something the hyperscalers can't: a genuine partnership. Alongside compute access, Dispersed was able to offer Paul compute credits, a grant-funded engineer to assist with integration, and ongoing support. This is the kind of arrangement, as Litvak notes, that simply isn't available from AWS or Google Cloud. For a lean nonprofit whose mission depends on processing such massive amounts of data, that support infrastructure matters as much as the compute itself.
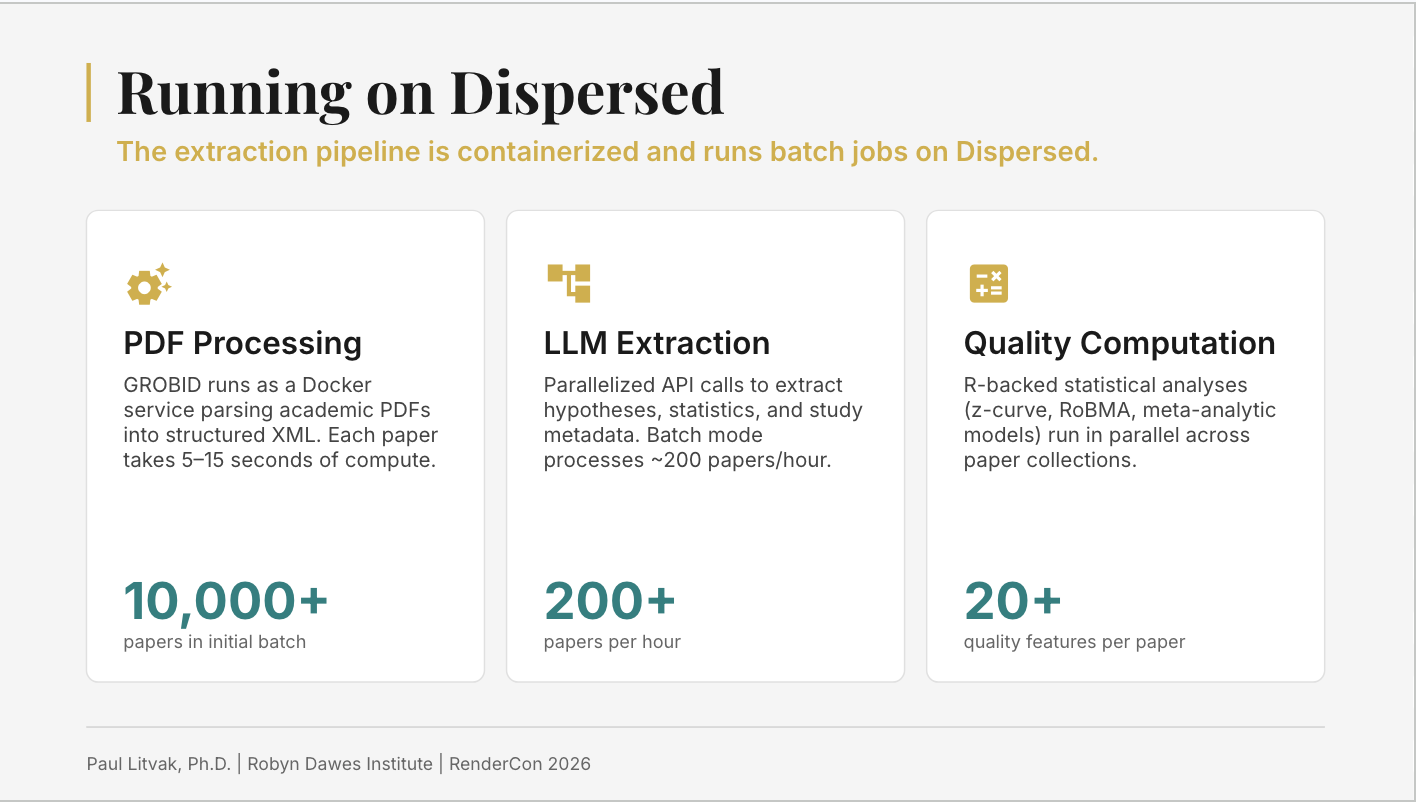
As evidence.guide scales from its current 10,000 psychology papers toward the eventual vision of processing every published RCT—millions of papers across medicine, economics, and beyond—the partnership with Dispersed becomes not just convenient but essential. The science can only go as far as the infrastructure allows.
When a paper is uploaded to evidence.guide, it enters the pipeline and moves through several distinct stages:
PDF Ingestion. Scientific papers are ingested in PDF format. The pipeline is designed to handle papers from a wide range of journals, time periods, fields, and reporting conventions.
GROBID Parsing. The paper passes through GROBID, which extracts structured data: authors, abstracts, references, statistical values, tables. At approximately 80% baseline accuracy, GROBID provides the foundation that subsequent layers refine.
LLM Refinement. This is where the pipeline gets more sophisticated, and where the hardest problems live. Large language models including Gemini and Mistral process the GROBID output, with tables fed directly into image models to improve extraction accuracy. But as Litvak notes, clean extraction is only the first hurdle: "You can get all the details of the table transcribed correctly and the LLM can still fail to comprehend what the cells in the table mean." Getting the numbers out and understanding what those numbers represent are two distinct problems, and the evidence.guide pipeline addresses both.
Extracting and interpreting numbers is only part of the picture. For the deeper layer of critique — whether a study's design actually supports its conclusions, whether the right things were measured, whether causal claims are justified — evidence.guide partners with Refine.ink, an AI peer review system. Refine runs an automated peer review pass on the paper, looking for evidence that the study may not have been conducted as rigorously as reported. It looks for problems with how the study was designed, what it actually measured, and whether its conclusions are justified by the data. Those findings feed directly into the replicability prediction model.
Statistical Verification. The statistical values that were extracted earlier are now run through a suite of forensic verification tests:
The findings from these tests feed the replicability prediction model alongside the qualitative signals from Refine.ink.
Replicability Prediction. All of the extracted features from the previous steps are fed into an XGBoost model trained on a ground truth dataset of roughly 4,000 replicated studies. The model outputs a replicability probability score for each paper.
The pipeline runs on Dispersed's distributed GPU network, enabling the compute-intensive LLM extraction and model scoring steps to run in parallel across multiple nodes simultaneously—the infrastructure backbone that makes processing at this scale economically viable.
Structured Output. Finally, the paper receives a score representing the probability that a study will replicate, along with the specific features that drove the prediction. This gives users not just a verdict, but the evidence behind it.

The replicability crisis is not a problem that can be solved by asking individual researchers to do better science. It is, at its core, an infrastructure problem: The existing literature is load-bearing, decisions are being made on top of it right now, and no manual process can evaluate it at a scale that actually matters. Evidence.guide is the tool Paul is building to address that. Dispersed is the infrastructure that makes it possible.
The path from here is clear. Psychology studies first, then development economics, then clinical medicine. Finally, down the line, Paul hopes to cover every RCT ever published. Each expansion requires more compute. More compute means more papers processed. More papers processed means better predictions. And better predictions mean something real: a clinician who knows which trials are too small to trust, a funder who can see whether research shows signs of data manipulation, a policymaker who knows whether the intervention they're funding has evidence that actually replicates in the real world.
As Litvak describes it, the goal is ambitious but straightforward: “a comprehensive, quality-weighted evidence base for science”. This is not just built for scientists, but for the people who rely on science to make decisions. The policymaker, the clinician, the journalist, the program officer who needs to know whether to trust a finding without reading the methods section of 40 papers.
"They have unused GPU capacity, we have a workload that fits it." That alignment between Dispersed's infrastructure and the evidence.guide mission is what makes the next step possible. “Stay tuned,” Paul says, to see what Robyn Dawes and Dispersed accomplish together.