
At RenderCon 2026, Sarson Funds and Manifest Network demonstrated how AI applications can dynamically access distributed GPU infrastructure through Dispersed to power real-time, multi-model workflows.
Their presentation focused on a growing shift in AI infrastructure design: instead of relying on permanently reserved cloud compute, AI agents can source GPU power programmatically from decentralized networks as workloads appear.
Using Dispersed’s distributed GPU marketplace, applications like Agent1 and Suma are able to spin up specialized hardware on demand for embeddings, inference, portfolio analysis, and market classification without maintaining idle infrastructure.
The result is a more scalable, privacy-preserving, and economically efficient model for AI applications.
Sarson Funds approaches the market from an investment perspective, focusing on decentralized physical infrastructure networks (DePIN). Their thesis is that token-incentivized hardware networks—including decentralized GPU infrastructure—represent one of the next major categories in crypto and AI.
Manifest Network provides the infrastructure layer that connects AI applications to decentralized compute resources.
Together, the companies demonstrated how applications can use Dispersed GPU infrastructure as the execution layer behind AI workloads. This allows agents and tools to dynamically select and provision compute resources across distributed networks.
Rather than depending exclusively on centralized hyperscalers, applications can route workloads to distributed GPUs available through Dispersed in real time.
Two applications showcased during the presentation illustrated how this architecture works in production:
Both applications use Dispersed GPUs to orchestrate multiple specialized model calls simultaneously.
Instead of treating a prompt as a single inference request, workloads are broken into separate GPU tasks that can be distributed across different hardware tiers depending on computational requirements.
Agent1 was presented as a privacy-focused AI assistant built on top of Dispersed GPU infrastructure.
Every user query fans out into three distinct GPU jobs running across distributed compute resources:
Embedding – a GPU model converts the prompt into semantic vector representations
Organization – another GPU workload routes context, prior conversations, and tools
Inference – a final GPU model generates the response using the user’s selected model
Dispersed enables these workloads to run on different GPU types depending on task complexity.
For example:
Lightweight embedding workloads may run on lower-cost GPUs like a 3060 Ti
High-performance inference workloads can scale to GPUs like a 5090
This workload-aware orchestration allows Agent1 to optimize both performance and infrastructure costs dynamically.
Manifest Network emphasized that Dispersed’s hourly pricing model and distributed GPU availability make it possible to scale compute usage in real time instead of maintaining expensive idle GPU capacity.
The system also incorporates:
The presentation framed this as a fundamental evolution in AI architecture.
Instead of operating as static software running on fixed infrastructure, AI agents become orchestration systems capable of sourcing compute dynamically through decentralized networks.
As presented during the session:
“The agent stops being a chatbot — it becomes a buyer of compute.”
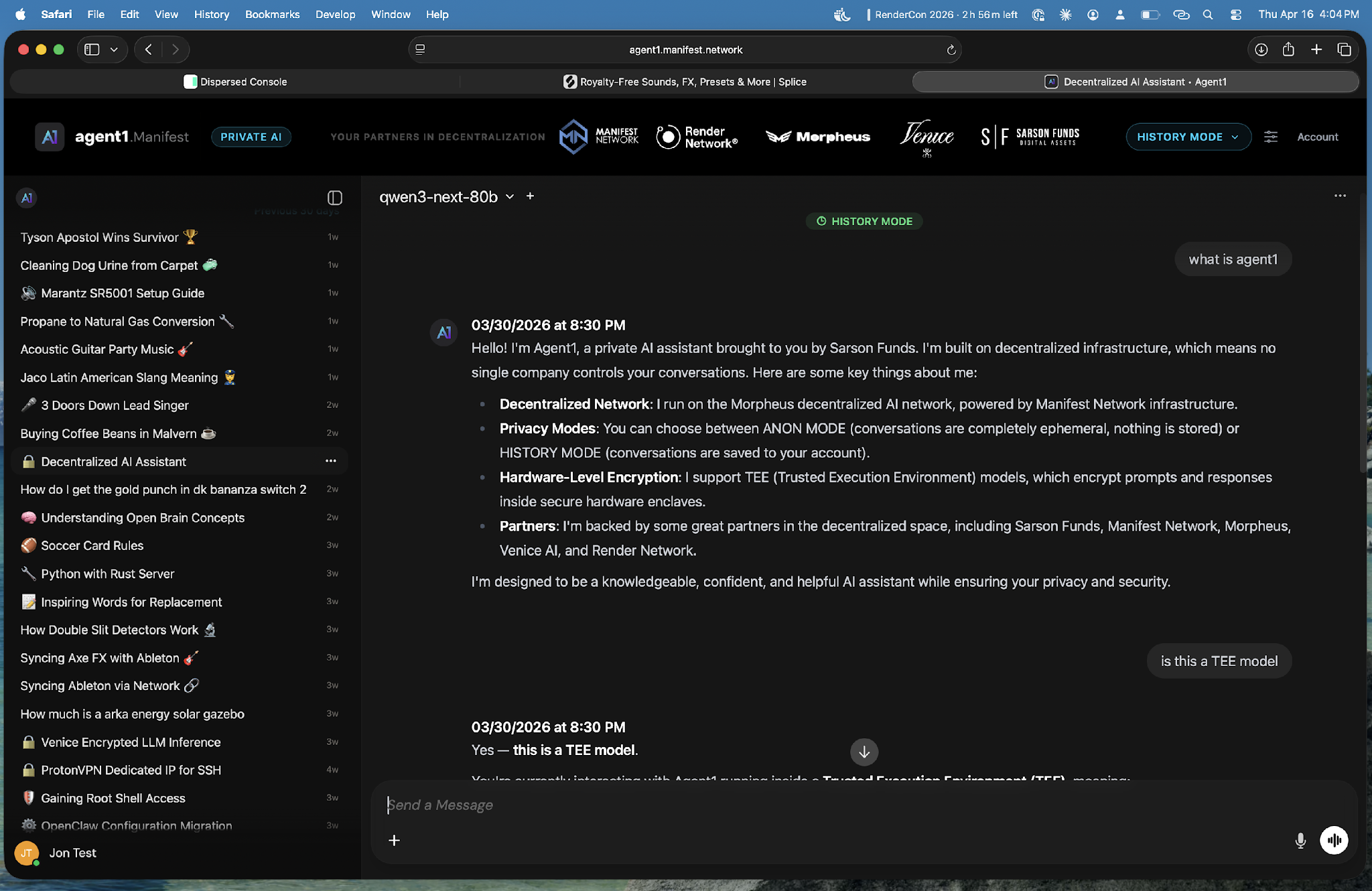
Caption: Agent1, an encrypted, multi-model AI assistant
Manifest Network emphasized several design principles behind Agent1:
The broader implication is that AI assistants no longer need to operate as isolated applications running on fixed infrastructure. Instead, they become orchestration layers capable of programmatically sourcing compute resources whenever needed.
As presented during the session:
“The agent stops being a chatbot — it becomes a buyer of compute.”
The second application demonstrated, Suma, applies the same Dispersed-powered infrastructure model to crypto portfolio analysis.
Suma uses Dispersed GPUs to run multiple AI systems side-by-side:
An analyst model processes portfolio holdings, allocations, and user questions
A Markov regime classifier evaluates broader market conditions simultaneously
Users can ask natural-language questions like:
“Should I hold ARB?”
“How exposed am I to market volatility?”
“What allocations are overweight?”
Behind the scenes, Dispersed GPUs execute the required workloads in parallel, allowing Suma to combine real-time financial analysis with market regime modeling.
The architecture enables different models to scale independently while selecting the most cost-efficient hardware available for each workload.
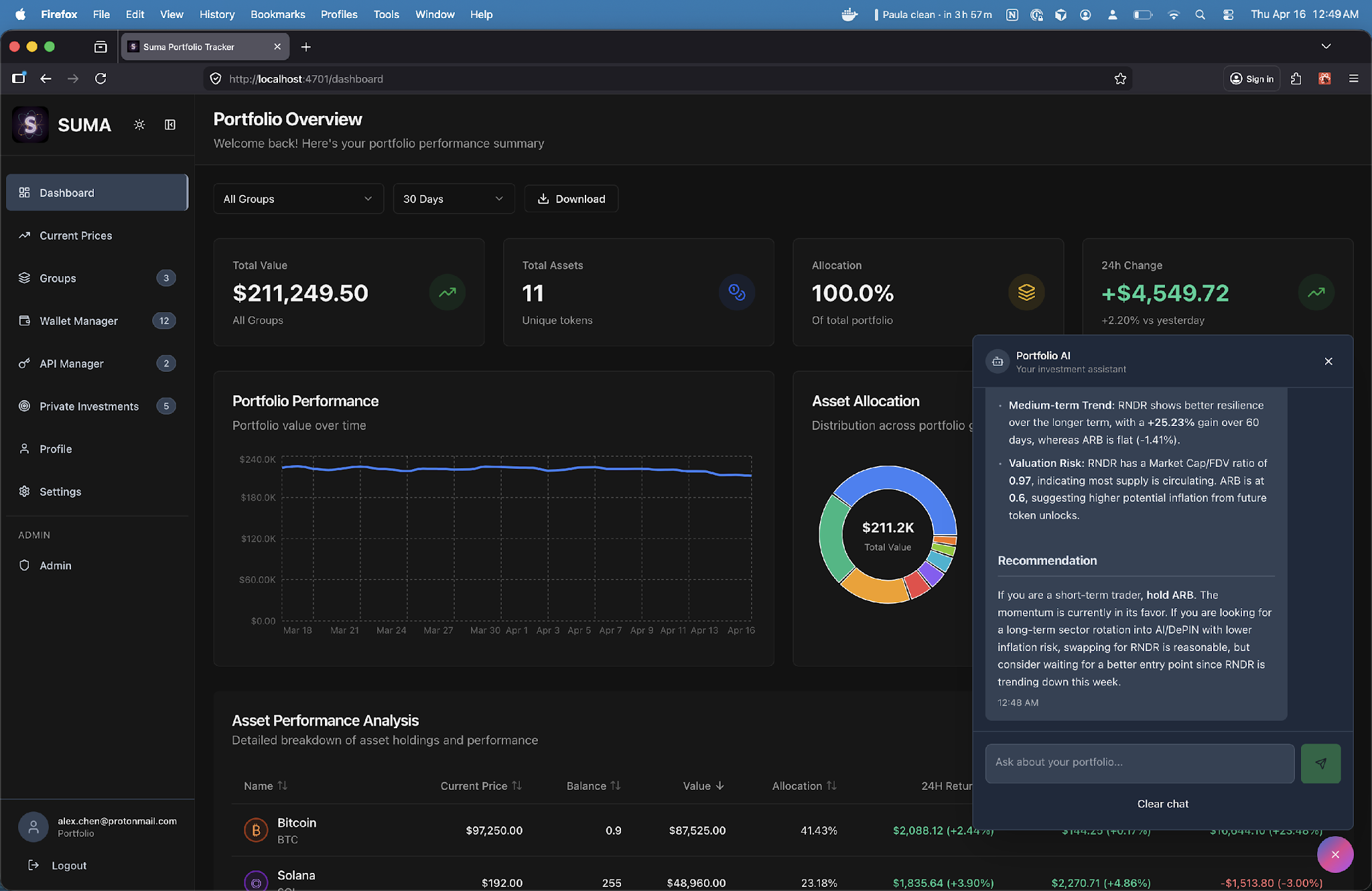
Caption: Suma (a crypto portfolio analysis tool)
By separating workloads across multiple GPU jobs, the system can independently optimize performance, cost, and model specialization.
A major theme throughout the presentation was production-grade GPU selection per workload.
Manifest Network demonstrated how applications can use Dispersed to provision different GPU tiers dynamically depending on computational requirements.
The presentation highlighted:
This becomes especially important for AI agents generating unpredictable or burst-heavy workloads.
Instead of overprovisioning cloud infrastructure, applications can pull compute resources from Dispersed only when needed.
That means AI systems can orchestrate multiple specialized GPU jobs per interaction without permanently maintaining expensive GPU clusters.
One of the most compelling concepts presented was the idea of AI agents acting as autonomous consumers of infrastructure.
Through integrations with open standards and OpenClaw-compatible tooling, Agent1 can dispatch jobs directly to Dispersed GPU resources in real time.
In this architecture:
Compute infrastructure effectively becomes liquid and programmatically accessible.
Rather than attaching fixed infrastructure to a single application, AI agents can continuously source compute from decentralized GPU networks based on current demand, pricing, and workload requirements.
The Sarson Funds and Manifest Network presentation highlighted how decentralized GPU infrastructure, like Dispersed, can support a new category of AI-native applications built around dynamic compute orchestration.
Key themes included:
As AI applications become increasingly complex, the ability to dynamically access specialized GPU resources may become foundational to how future AI systems operate.
By combining encrypted workflows, distributed GPU orchestration, and on-demand infrastructure provisioning through Dispersed, Manifest Network’s architecture points toward a future where AI agents actively source and consume compute resources in real time, turning decentralized GPU infrastructure into a programmable utility layer for AI.